Slack applies GenAI to Spark operations, cutting cloud costs and speeding analytics across its global data platform.
Slack processes terabytes of analytics data daily using Apache Spark on Amazon EMR. As data volumes grew, performance tuning became slow, manual, and expensive. As a result, engineers struggled with cryptic logs, fragmented metrics, and reactive troubleshooting. Because of that GenAI addressed this challenge by transforming Spark optimization from guesswork into a deterministic, data-driven process that scales with Slack’s infrastructure.
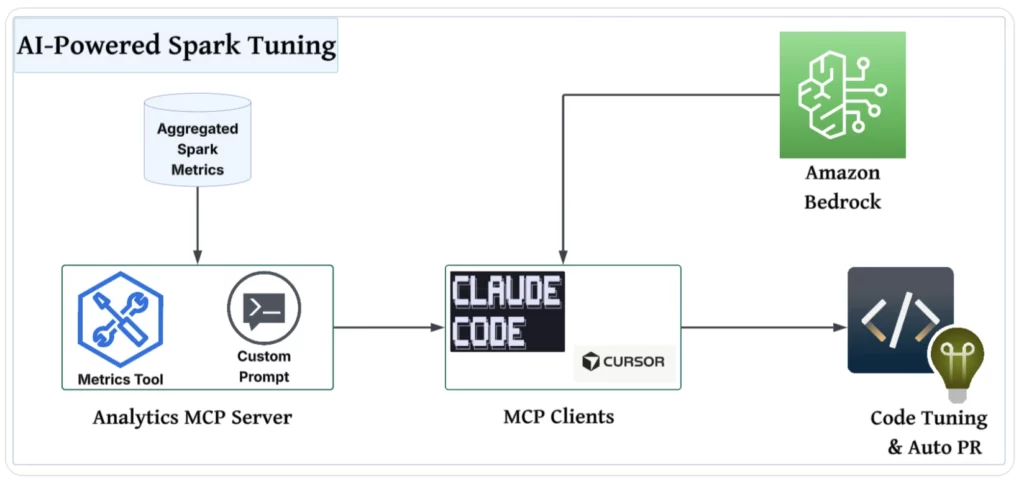
Slack built a GenAI enabled monitoring framework capturing more than 40 Spark metrics across applications, jobs, stages, and tasks. These metrics flow through Kafka. As well as Apache Iceberg, and Spark SQL pipelines. GenAI models, hosted securely on Amazon Bedrock, analyze this enriched telemetry. The system interprets skew, memory spills, retries, and configuration gaps that traditional tools frequently miss.
To operationalize insights, Slack integrated GenAI directly into developer workflows. A custom metrics tool and structured prompts connect Spark data with AI-assisted coding tools like Claude Code. Developers receive environment-aware recommendations, automated configuration updates, and ready-to-review pull requests. Strict prompt design ensures reproducible outputs and minimizes hallucinations in performance guidance.
The results demonstrate GenAI’s operational impact. Slack reduced Spark compute costs by 30 to 50 percent and accelerated job completion by 40 to 60 percent. Developer time spent on tuning dropped by more than 90 percent. By pairing governed data pipelines with generative and agentic AI, Slack moved from reactive monitoring to proactive optimization, improving reliability while lowering infrastructure spend at global scale.
This case matters because it shows GenAI evolving from a productivity assistant into an operational intelligence layer for complex enterprise systems. Beyond Slack, it reflects a widespread enterprise challenge: optimizing large-scale data infrastructure where performance issues are costly, difficult to diagnose, and heavily dependent on scarce expert knowledge. The case represents the problem of turning massive volumes of low-level telemetry into actionable decisions in real time. By embedding GenAI into governed data pipelines and developer workflows, organizations can shift from reactive troubleshooting to proactive optimization, reducing costs, improving reliability, and scaling expertise without proportionally increasing engineering headcount.


